Ignorando o BPE: Tokenização Contínua via Convoluções Causais Aceleradas por Triton
Introdução
A tokenização discreta de subpalavras é uma fonte fundamental de ruído e sobrecarga de parâmetros em modelos de linguagem modernos. O Byte Pair Encoding (BPE) cria representações fragmentadas que degradam as relações semânticas entre palavras morfologicamente relacionadas e introduzem vulnerabilidade a pequenas variações ortográficas.
Este artigo detalha a arquitetura do FuzzyTok, um tokenizador contínuo que substitui os mapeamentos de vocabulário discreto por vetores latentes densos e sensíveis ao contexto, gerados dinamicamente a partir de fluxos de bytes UTF-8 brutos.
Arquitetura
O FuzzyTok utiliza blocos residuais empilhados de convoluções causais 1D com taxas de dilatação de crescimento exponencial. Esta configuração resulta em um campo receptivo efetivo de 43 caracteres, permitindo que o modelo capture morfemas, prefixos e sufixos. As representações são subsequentemente mapeadas para um espaço latente contínuo através de uma projeção linear.
A causalidade temporal é estritamente mantida, garantindo que a representação de saída em cada passo dependa apenas dos bytes de entrada atuais e anteriores.
Otimizações com OpenAI Triton
A implementação eficiente de convoluções causais dilatadas em kernels CUDA customizados exige um gerenciamento de memória cuidadoso. O principal gargalo é a latência de acesso à VRAM global.
Nosso kernel Triton customizado aborda esse problema por meio de 2D Channel Tiling (Ladrilhamento de Canais 2D):
- As dimensões dos canais de entrada e saída são particionadas em blocos de 32x32.
- Os blocos são carregados na memória SRAM on-chip rápida, onde as acumulações parciais são executadas usando instruções de aritmética de matriz nativas dos Tensor Cores (
tl.dot). - Índices temporais negativos fora dos limites da sequência são resolvidos usando uma máscara de fixação causal (
tl.where), evitando divergências e falhas de segmentação. - Os tamanhos dos blocos são limitados a 32 para evitar o vazamento de registradores (register spilling) da GPU, o que degradaria a vazão de processamento (throughput) da execução.
Benchmarks Experimentais (NVIDIA Tesla T4)
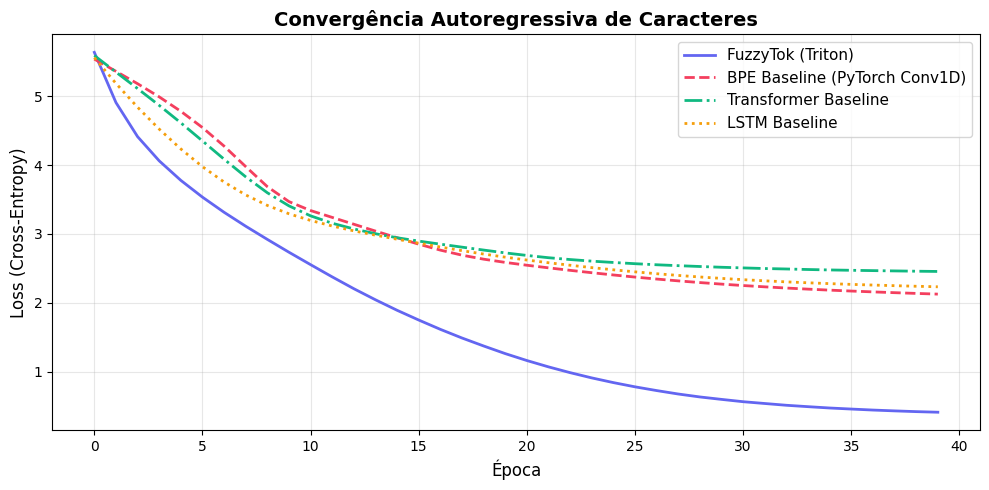
Avaliamos o FuzzyTok em comparação com baselines de tamanho de parâmetros equivalente, treinados para previsão do próximo caractere ao longo de 40 épocas:
- Convergência: O FuzzyTok alcançou uma perda de entropia cruzada final de 0,4110 (Perplexidade: 1,51), comparado a 2,1257 (Perplexidade: 8,38) do BPE Conv1D, 2,2320 (Perplexidade: 9,32) do LSTM e 2,4547 (Perplexidade: 11,64) do Transformer.
- Consumo de Memória: O gerenciamento de ativação fundida (fused activations) no Triton gerou uma economia de VRAM de 38,1% em comparação com o PyTorch Conv1D. Em configurações de contexto longo (B=32, T=2048), o FuzzyTok utilizou 392,7 MB de VRAM contra 9,24 GB do Transformer, uma redução de 95,7% de memória.
- Vazão (Throughput): O kernel Triton otimizado processou 195 mil tokens/segundo sob carga máxima, alcançando uma redução de 4,16x no tempo total de treinamento em comparação com o kernel não otimizado.
- Qualidade de Representação: A taxa de separação por similaridade de cosseno entre palavras cognatas e não relacionadas atingiu 1,1143, indicando uma alta coesão morfológica no espaço contínuo.
Conclusão
O FuzzyTok demonstra que a tokenização livre de vocabulário é uma alternativa computacionalmente viável, eficiente em termos de memória e altamente convergente para modelagem de linguagem. O design de kernels de GPU customizados com Triton preenche a lacuna de desempenho entre o processamento de bytes brutos e as arquiteturas tradicionais de incorporação de subpalavras.
Anexado nesse post, temos o paper completo e a documentação.